有了 HTTP 协议,为什么还要 RPC?
你好,我是小 G。在我大二下学期那年,看黑马的免费课程,第一次接触到 RPC,当时还是挺懵逼的。
HTTP 接口不是已经能调了吗?
前端调后端是 HTTP,服务端调服务端也可以用 HTTP。写一个 /user/getById 接口,传个用户 ID,返回用户信息,这不也能完成远程调用吗?
那为什么还要再搞一个 RPC 增加学习成本呢?这不纯闹嘛!
更容易让人混乱的是,很多文章特别喜欢把 HTTP 和 RPC 放在一起对比,好像它们是同一层的两个协议。看完之后你可能记住了几句话:HTTP 面向资源,RPC 面向方法;HTTP 对外,RPC 对内;RPC 性能更好。
这些话不是完全错,但太粗了。
真到项目里,你还是会遇到问题:用 HTTP 行不行?用 RPC 是不是过度设计?gRPC 明明基于 HTTP/2,为什么又说它是 RPC?
这篇文章就围绕这个问题聊清楚。
RPC 不是某一个具体协议
这是一个常见的误区,开始后面的文章之前,非常有必要先提一下。
HTTP 是协议。而 RPC 不是某一个具体协议,它更像是一种调用方式。
RPC 全称是 Remote Procedure Call,翻译过来就是远程过程调用。它想解决的问题很朴素:让你调用远程服务时,尽量像调用本地方法一样。
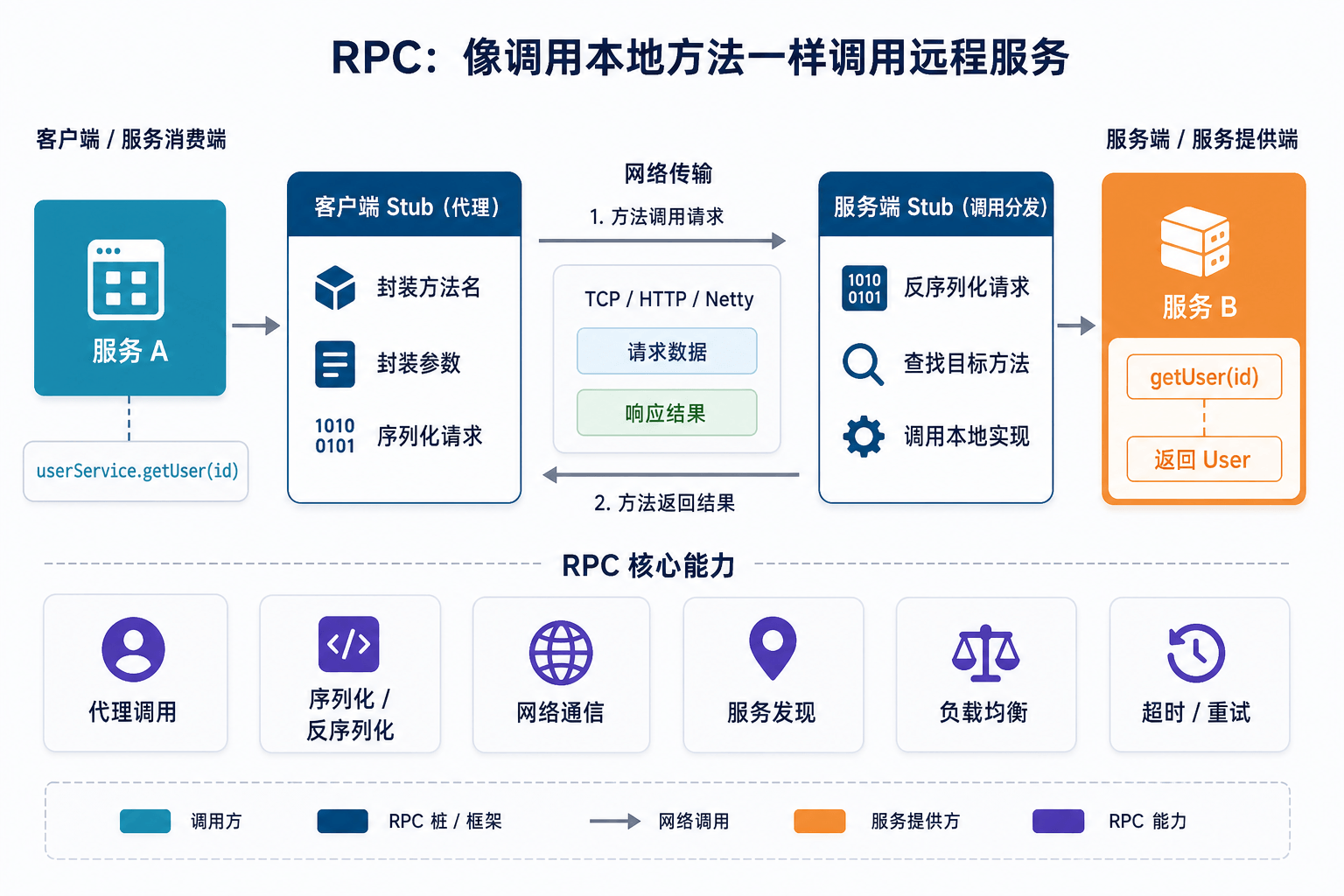
比如本地代码里调用用户服务:
User user = userService.getUser(1001);
如果 userService 就在当前进程里,这只是一次普通方法调用。
但如果用户服务部署在另一台机器上,这件事就复杂了。你要发网络请求,要传方法名和参数,要序列化数据,要处理超时、失败、重试,还要拿到返回结果再反序列化。
RPC 框架想做的事情,就是把这些麻烦尽量封装掉。调用方代码看起来还是:
User user = userService.getUser(1001);
但底下已经完成了网络通信、序列化、服务寻址和结果返回。
所以更准确的说法不是“HTTP 和 RPC 谁更强”,而是:
HTTP 是一种应用层协议,RPC 是一种远程调用模型。
具体到实现上,RPC 可以有很多种。Dubbo 是 RPC 框架,Thrift 是 RPC 框架,gRPC 也是 RPC 框架。gRPC 官方文档里也说得很直接:客户端可以像调用本地对象一样,调用另一台机器上服务端应用的方法;服务端定义可远程调用的方法以及参数和返回类型。

这就解释了一个很容易绕晕的点:gRPC 是 RPC,但它基于 HTTP/2。
它不是 HTTP 的反面,只是在 HTTP/2 之上提供 RPC 调用。
gRPC 的 GitHub 上专门有一篇文章 gRPC over HTTP2 基于 HTTP2 的 gRPC 协议 详细介绍:
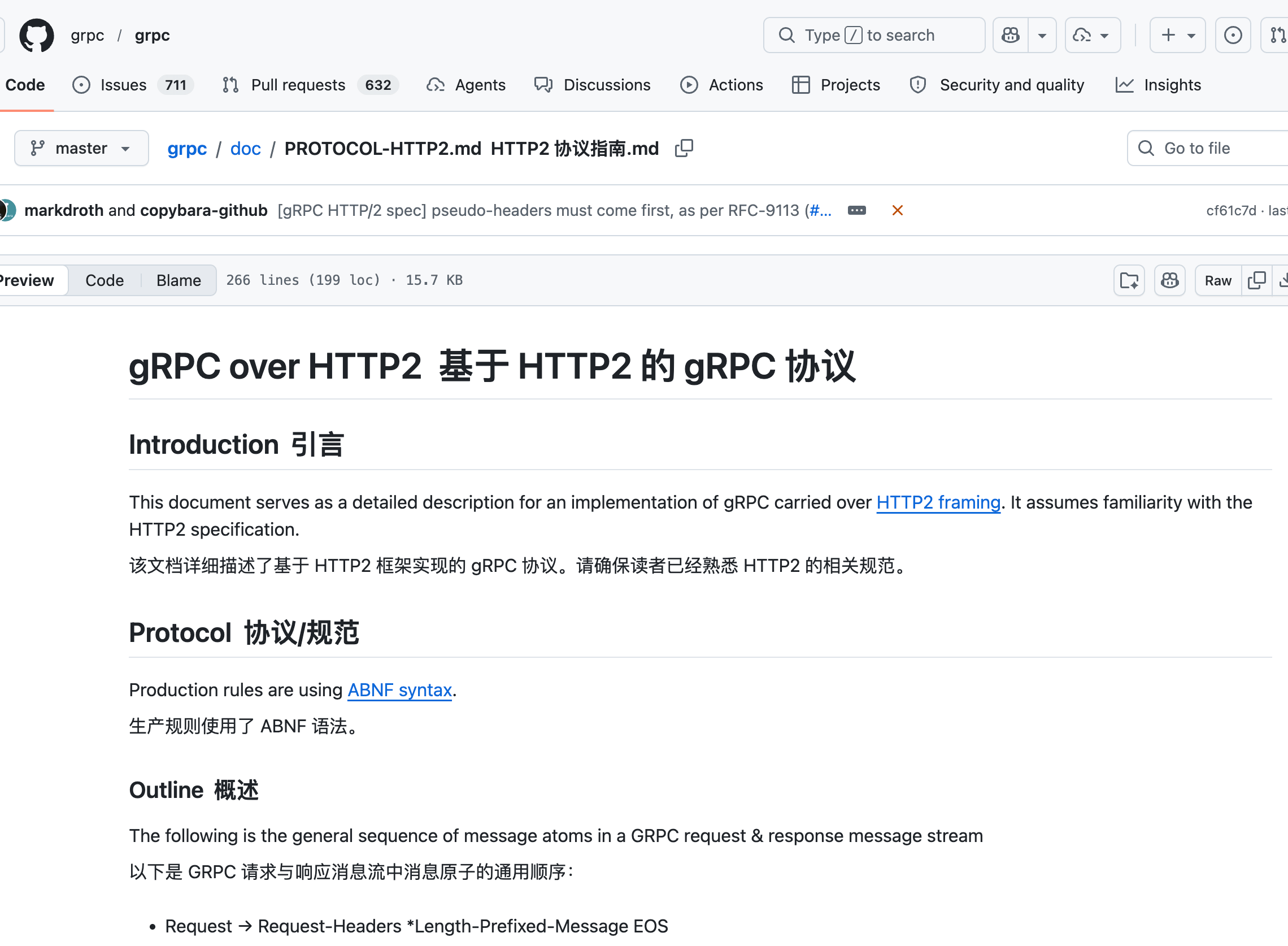
光有 TCP 还不够
要理解 HTTP 和 RPC 的差别,最好先往下看一层。
很多同学知道 HTTP 基于 TCP,RPC 也经常基于 TCP,于是会想:那我直接用 TCP 不就行了吗?
理论上可以,实际很麻烦。
TCP 负责的是可靠传输,它传的是一串连续的字节流。它不关心你的业务消息从哪里开始,到哪里结束。
比如客户端连续发了两次请求:
getUser:1001
getOrder:8888
服务端收到的可能不是两段规规整整的消息,而是一段字节流。你必须自己判断:第一条消息在哪里结束,第二条消息从哪里开始。还要考虑半包、粘包、编码、超时、错误码、请求 ID 等问题。
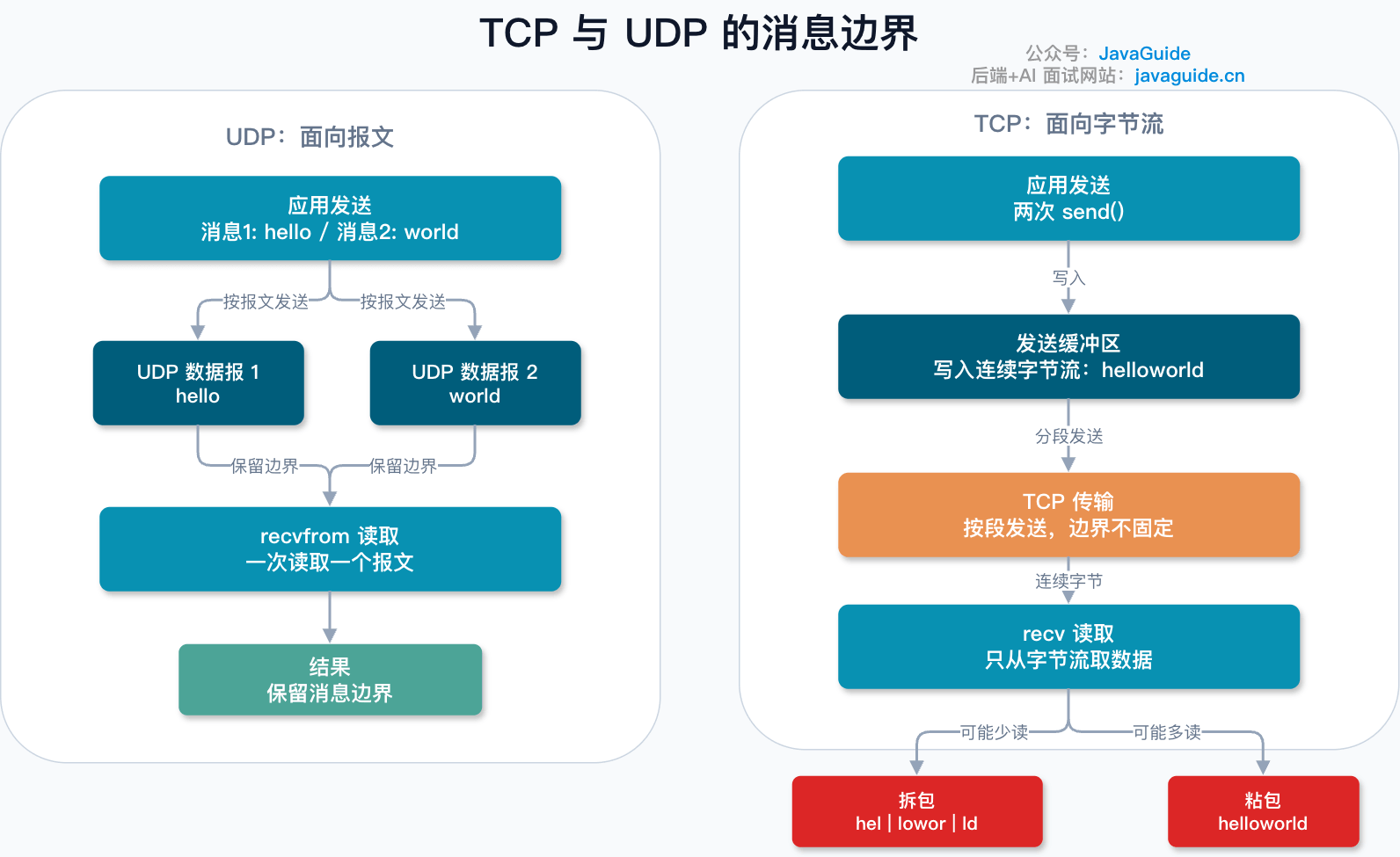
这就是为什么应用层协议一定要定义消息格式。
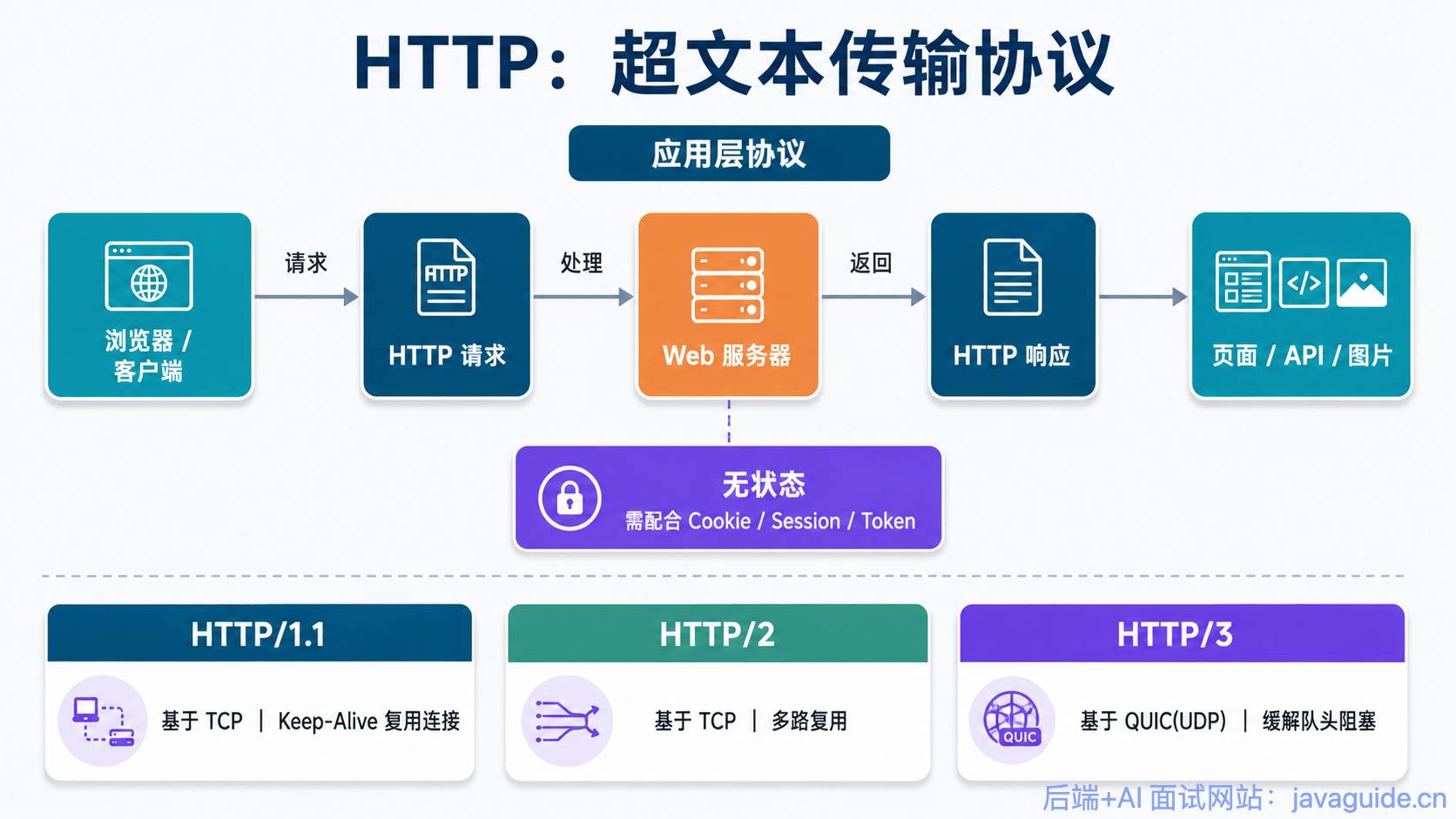
HTTP 定义了一套通用格式:请求行、Header、Body、状态码等。MDN 对 HTTP 的定义也很清楚:它是应用层协议,最初用于浏览器和 Web 服务器通信,但也可以用于机器之间通信和 API 访问。
RPC 框架也会定义自己的消息格式。只不过它通常不会围绕 URL 和资源来设计,而是围绕服务、方法、参数和返回值来设计。
说白了,HTTP 和 RPC 都在解决一个问题:
两个进程隔着网络,怎么把一次业务调用说清楚。
只是它们的建模方式不一样。
HTTP 更像访问资源,RPC 更像调用方法
HTTP / REST 常见写法是这样的:
GET /users/1001
POST /orders
PUT /orders/888/status
DELETE /comments/9527
它的心智模型是资源。
/users/1001 是一个用户资源,GET 表示读取它;POST /orders 表示创建订单;PUT /orders/888/status 表示修改订单状态。
这种方式很适合对外开放 API。
因为它通用、好理解、好调试。浏览器能访问,Postman 能调,curl 能测,网关也好处理。你给第三方提供接口时,让对方按 HTTP 文档接入,门槛比较低。
RPC 的写法更像这样:
userService.getUser(1001);
orderService.createOrder(request);
inventoryService.deductStock(skuId, count);
它的心智模型是方法调用。
调用方更关心的是:我要调哪个服务?哪个方法?传什么参数?返回什么对象?
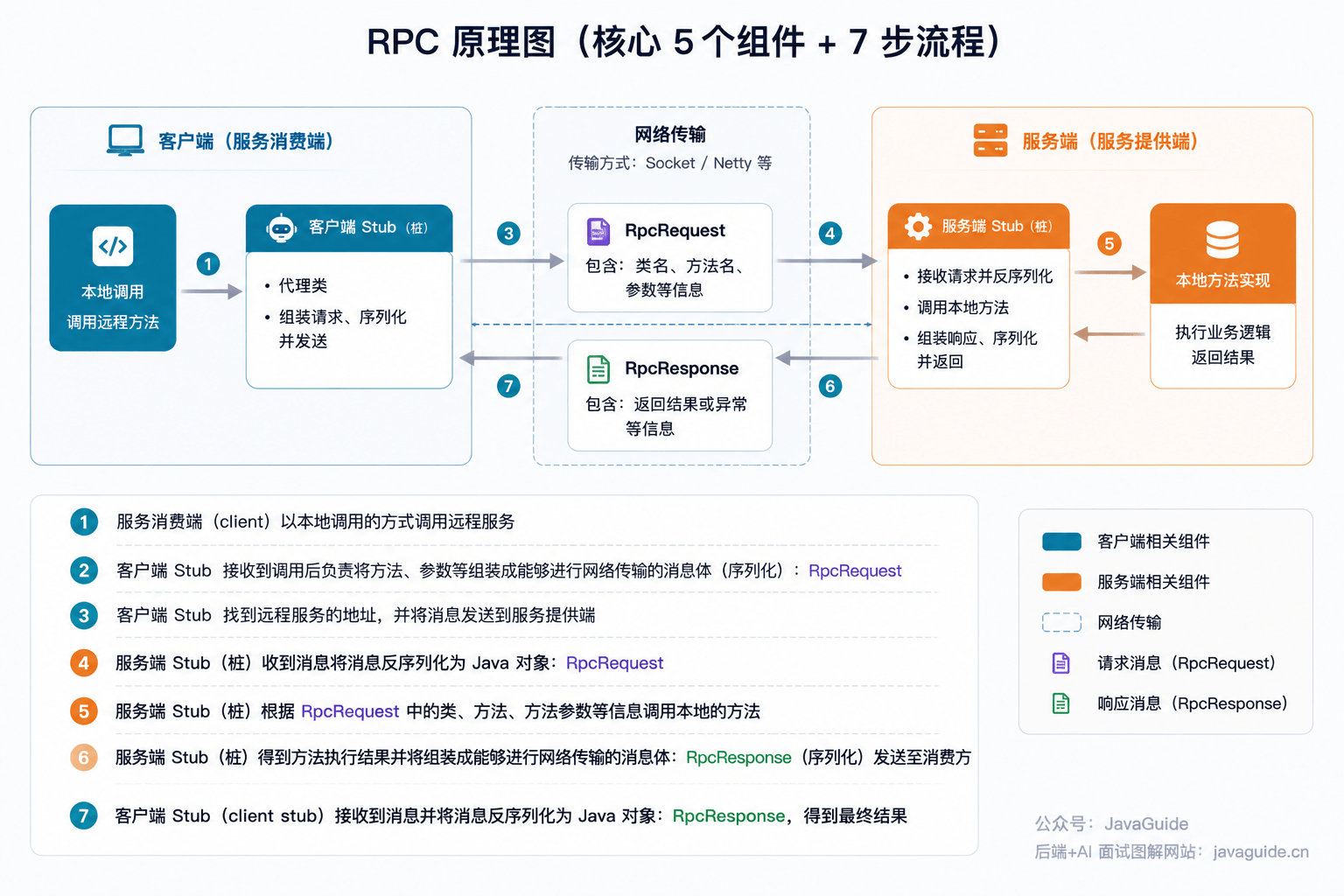
这和 Java 后端平时写代码的习惯更接近。尤其是微服务内部调用时,服务和服务之间本来就是围绕业务方法协作,比如创建订单、扣库存、查询余额、校验权限。RPC 把这种调用关系表达得更直接。
所以 HTTP 和 RPC 最大的区别,不是一个能不能调通,另一个能不能调通。
两者都能调通。
区别在于:你是把远程交互建模成一次资源访问,还是一次方法调用。
公司内部为什么更常见 RPC?
HTTP 当然能做内部服务调用。
很多公司内部服务全用 HTTP,也跑得好好的。尤其是服务规模不大、调用链不复杂的时候,HTTP 更简单。
但服务数量上来之后,RPC 的优势会慢慢变明显。
第一个明显变化是:调用方不想关心对方机器在哪。
你写业务代码的时候,最好只关心“我要调用用户服务”,而不是关心用户服务有几台机器、IP 是什么、哪台刚下线、哪台权重高。
这就需要服务发现。
Dubbo 官方文档里对服务发现的描述很典型:Provider 把地址注册到注册中心,Consumer 从注册中心读取并订阅地址列表,地址变化时注册中心通知消费者。Dubbo 支持 Nacos、Consul、ZooKeeper 等常见注册中心。
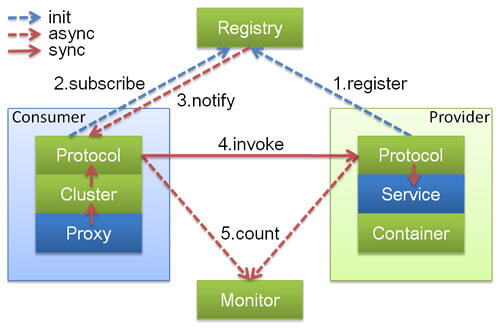
这类能力当然也可以用 HTTP 做。你可以用注册中心、网关、负载均衡、SDK 自己拼一套。
但 RPC 框架通常会把这些东西直接放进服务调用体系里。
调用方写的是服务接口,底下自动完成服务发现、负载均衡、连接管理、超时控制。业务代码不用到处拼 URL。
第二个变化是:接口契约会变得更重要。
HTTP + JSON 很灵活,但灵活也意味着容易松散。
字段名改了,类型改了,枚举值多了一个,调用方可能到运行时才炸。接口文档如果没及时更新,联调时就会很痛苦。
RPC 框架通常会用更强的契约来约束双方。以 gRPC 为例,它常用 Protocol Buffers 作为接口定义语言和消息交换格式。Protocol Buffers 官方文档也说明,它是一种语言无关、平台无关、可扩展的结构化数据序列化机制,可以通过 .proto 定义结构并生成不同语言的代码。
这带来的好处是,接口变更更容易被代码生成和编译阶段暴露出来。
当然,契约强不代表不会出事故。
字段怎么兼容,老版本客户端怎么处理,新字段能不能删,枚举能不能改,这些还是要认真设计。只是相比“大家约定一下 JSON 字段”,IDL 会更硬一点。
第三个变化是:高频内部调用会更在意机器处理效率。
HTTP + JSON 的好处是可读性强,人类看起来舒服。但机器处理时,它不是最省的方式。字段名、文本格式、解析成本,都会带来额外开销。
RPC 框架常用二进制序列化,比如 Protobuf、Thrift。体积更小,解析也更适合机器处理。
但这里不能说死。
“RPC 一定比 HTTP 快”这句话不严谨。HTTP/2、连接复用、压缩、不同 JSON 库、不同网络环境,都会影响结果。gRPC 自己也基于 HTTP/2,它的优势并不是一句“不是 HTTP”就能解释完。
更稳的说法是:
在高频服务互调场景里,RPC 框架通常会把序列化、连接复用、超时、重试、负载均衡、链路追踪这些能力做得更贴近内部服务调用。
这才是它在公司内部常见的原因。
RPC 的价值不只是“调用快一点”
很多人讲 RPC,喜欢把重点放在性能上。
性能当然重要,但我觉得 RPC 更大的价值是服务治理。
一个内部调用真正上线后,不只是发请求、拿响应这么简单。你很快会遇到一堆问题:
- 这个调用超时时间设多少?失败了要不要重试?重试会不会导致重复扣款?
- 下游服务挂了,上游要不要降级?
- 哪个接口最近错误率升高了?
- 一次用户请求经过了几个服务?
这些问题如果全靠业务代码处理,很快就会乱。
RPC 框架通常会和治理能力绑在一起,比如超时控制、负载均衡、服务发现、熔断降级、链路追踪、调用统计等。gRPC 官方介绍里也提到,它支持负载均衡、Tracing、健康检查和认证等可插拔能力。
HTTP 也能做这些。
很多公司会用 API Gateway、服务网格、HTTP SDK、拦截器、链路追踪组件来补齐。做得好也没问题。
所以不要把 RPC 理解成“比 HTTP 高级的东西”。它更像是把内部服务调用里常见的一堆问题,按“远程方法调用”这条路径整理了一遍。
那 HTTP 就不适合内部调用吗?
并不是的哈。如果服务规模不大,团队人数也不多,反而用 HTTP 更省心。
比如一个后台管理系统,拆了几个服务,调用频率也不高。你用 Spring Boot 写几个 REST 接口,配合 OpenAPI 文档、统一错误码、网关鉴权、日志追踪,完全够用。
强上 RPC 可能还会带来额外成本,没意义。
你要引入注册中心,要维护 IDL,要处理代码生成,要培训团队,还要解决本地调试和网关转发问题。服务没几个,调用链也不复杂的时候,这些成本不一定值得。
HTTP 适合这些场景:
- 对外开放 API,比如 Web、App、第三方合作方接入;
- 团队更看重通用性和调试方便;
- 服务调用频率不高;
- 没有成熟 RPC 基础设施;
- 已经有统一 HTTP 网关、SDK、限流、鉴权和监控体系。
这里有个很简单的判断,分享给大家:
如果你的系统用 HTTP 已经稳定跑着,也没有明显的调用治理痛点,就没必要为了“微服务味更浓”换 RPC。
技术选型不是贴标签。
能稳定解决问题更重要。
gRPC 为什么容易把人绕晕?
gRPC 经常让人混乱,就是因为它同时踩在两个概念上。
一方面,它是 RPC 框架。
你定义服务和方法,生成客户端和服务端代码,然后像调用方法一样调用远程服务。
另一方面,它基于 HTTP/2 传输。
所以你不能把它简单理解成“HTTP 的对立面”。
更准确地说: gRPC 用 HTTP/2 做传输,默认使用 Protobuf 作为 IDL 和消息序列化格式,再用 RPC 模型组织调用。
这里要注意,Protobuf 是 gRPC 最常见的默认搭配,但不是 gRPC 的定义本身。gRPC 协议层允许 application/grpc+proto、application/grpc+json 或自定义编码。
还有一点经常被忽略:正常 gRPC 响应里,HTTP 层通常是 :status: 200,真正的调用结果放在 HTTP/2 Trailers 里的 grpc-status、grpc-message。
这会带来一个很实际的排查差异。
看 HTTP 接口时,我们习惯先看 HTTP 状态码。200 基本代表请求成功,404 代表资源不存在,500 代表服务端异常。
但看 gRPC 时,不能只看 HTTP 状态码。HTTP 是 200,不代表这次 RPC 业务调用一定成功,还要继续看 grpc-status。
这也带来一个工程问题:网关、负载均衡、代理、Service Mesh 是否正确支持 HTTP/2 Trailers,会直接影响 gRPC 调用。如果链路里有组件处理不好 Trailers,问题会很隐蔽。
所以,gRPC 不是“HTTP/2 + Protobuf”这么简单。
HTTP 这一层,它跑在 HTTP/2 上。
编码上,默认搭配 Protobuf,但协议允许其他编码。
调用体验上,它让你像调本地方法一样调远程服务。
状态返回上,它又用了 HTTP/2 Trailers 承载 RPC 调用结果。
这些东西叠在一起,才是它容易把人绕晕的原因。
真实选型时,别问哪个更高级
我更建议你按调用关系选:
- 如果是浏览器、移动端、第三方系统调用,优先 HTTP。原因很简单:通用,接入成本低,调试工具多。对外接口最怕别人接不动。HTTP 在这方面优势太明显了。
- 如果是公司内部微服务高频互调,可以考虑 RPC。尤其是服务数量多、接口数量多、调用链复杂,对超时、重试、注册发现、链路追踪、负载均衡要求都比较高的时候,RPC 框架会省掉很多重复工作。
- 如果团队已经有成熟 HTTP 基础设施,也没必要强上 RPC。比如统一网关、服务发现、SDK、链路追踪、限流熔断都有了,大家也习惯用 HTTP,那继续用 HTTP 没问题。
如果要用 gRPC,要提前想清楚几个问题:
- 浏览器不能像后端服务一样直接使用标准 gRPC,通常需要 gRPC-Web 或代理层;
- 网关和负载均衡是否支持;本地调试是不是方便;
- 团队是否接受
.proto和代码生成; - 线上排查时二进制消息是否会增加理解成本。
gRPC 很强,但不是零成本。
这点要提前说清楚。
几个常见误解
HTTP 和 RPC 谁性能更好?
不能一刀切。
如果拿 HTTP/1.1 + JSON 去和基于 HTTP/2 + Protobuf 的 gRPC 比,在高频内部调用场景里,后者通常更省。
但换个实现,结果就可能不一样。
消息大小、序列化方式、连接复用、压缩、框架实现、网络环境都会影响结果。真正要比,应该拿你自己的接口、数据量和部署环境压测,而不是背一句“RPC 更快”。
RPC 是不是只能走 TCP?
不是。
RPC 是调用模型,不是传输协议。它可以基于 TCP,也可以基于 HTTP/2。gRPC 就是一个很典型的例子。
REST 和 RPC 是不是互斥?
不完全互斥。
REST 更偏资源建模,RPC 更偏方法调用。实际项目里经常混用:外部接口走 REST,内部服务走 RPC。这很正常。
有了 HTTP/2,还需要 RPC 吗?
HTTP/2 在 HTTP 这一层引入了帧、流、多路复用、头部压缩等能力,提高了同一条 TCP 连接上的并发利用率。
但它不会自动帮你定义服务接口,不会自动生成客户端代码,也不会自动解决服务发现、超时重试、调用治理和版本契约。
还有一个很容易被忽略的差异:调用模式。
普通 HTTP API 大多是一问一答。gRPC 除了最常见的 Unary 调用,还原生支持服务端流、客户端流和双向流。gRPC 官方文档也明确列出了 Unary、Server streaming、Client streaming、Bidirectional streaming 这四种调用模式。
比如日志订阅、长任务进度推送、批量上传、实时同步这类场景,用 streaming 会更自然。你当然也可以用 SSE、WebSocket,或者自己基于 HTTP/2 封装,但那就相当于又在补 RPC 框架已经做好的那部分能力。
所以 HTTP/2 很重要,但它不是 RPC 框架的全部。
gRPC 是不是等于 HTTP/2 + Protobuf?
不是。
这句话只能用来帮助初学者快速建立印象,不能当严格定义。
更准确的说法是:gRPC 基于 HTTP/2 承载 RPC 调用,默认使用 Protobuf 描述接口和消息,但协议本身允许 JSON 或自定义编码;同时,它还定义了请求路径、Content-Type、Length-Prefixed-Message、Trailers 里的 grpc-status 等一整套规则。
所以 gRPC 不是单纯换了一个序列化格式,它是一套 RPC 调用协议和工程约定。
最后
HTTP 和 RPC 不是谁取代谁的关系,也不是谁更高级的问题。
HTTP 能调服务,RPC 也能调服务。真正的区别在于,你是想把远程调用当成一次“资源访问”,还是当成一次“方法调用”。
如果是对外接口,比如 Web、App、第三方系统接入,HTTP 通常更合适。它通用、好调试、接入成本低,别人拿 Postman、curl 就能测。
如果是公司内部服务互调,尤其是服务多、调用链长、接口频繁调用,还要考虑服务发现、超时、重试、负载均衡、链路追踪这些问题,RPC 会更顺手一些。它不是单纯为了快,而是把内部服务调用里的很多麻烦事一起处理掉。
所以,别再简单背“HTTP 对外,RPC 对内”了。
这句话可以帮助入门,但真做项目时,还得看你的调用对象、团队基础设施、排查成本、性能要求和后续维护成本。
系统规模不大,用 HTTP 已经跑得很稳,就别为了“看起来更微服务”强上 RPC。
内部调用越来越复杂,HTTP SDK、网关、监控、重试这些东西越补越多,那就可以认真考虑 RPC。
一句话:HTTP 没那么弱,RPC 也没那么神。选哪个,主要看它能不能用更低成本解决你现在的问题。